Un mes atrás publiqué un ejemplo con VBA de cómo conseguir pasar cadenas de texto a matriz.
En el artículo de hoy conseguiremos lo mismo pero solo con fórmulas!!
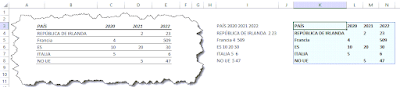
¿Cuántas veces hemos copiado o exportado datos de un pdf y nos ha devuelto la 'supuesta tabla' como una cadena de valores no respetando la dsitribución de columnas?... Muchas veces el problema es el cómo se generó esa tabla y se insertó en el documento y otras simplemente falla el OCR de lectura del pdf.
El caso es que lo que tenemos en nuestra hoja de cálculo es un rango de celdas, cada una con una cadena de texto con la secuencia de la columnas dispuestas seguidas... como vemos en la imagen anterior :'(
Veamos cómo con una 'formulita' conseguiremos convertir esas celdas en la matriz original esperada.
Lo primero es buscar patrones en esas celdas...
Observamos que hay en primer lugar, tanto para encabezados como para datos, una secuencia de palabras que queremos se conviertan en la primera columna.
Y el resto de datos, numéricos o vacíos, serán el resto de columnas (en mi ejemplo corresponderán a los tres años dispuestos).
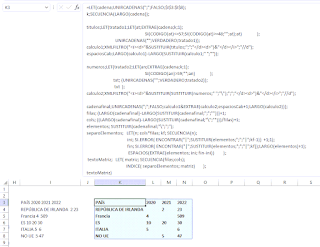
Como puedes comprobar en la imagen la fórmula no es pequeña... no puede ser de otra forma, ya que el trabajo que realiza es complejo:
1- segrega la primera parte de textos (el PAÍS) independientemente de las palabras que contenga.
Puedes verificar en la imagen que hay paises escritos de distintas formas con 1,2,3, ... palabras
2- extrae las columnas de años respetando aquellas que no tengan valor.
3- unimos ambas para componer nuestra matriz final.
Te recomiendo para los dos primero puntos revises estas dos entradas del blog:
Recuperar textos
Recuperar números
Son técnicas que emplearemos en la fórmula siguiente:
Analicemos nuestra fórmula por partes...
En primer lugar identificamos el rango de celdas y lo concatenamos con la función UNIRCADENAS, para a continuación realizar un conteo de caracteres total... necesario para posteriormente proceder a una extracción caracter a caracter:
En segundo lugar recuperaremos, bajo cualquier condición (dará igual el número de palabras que tenga) la lista de paises, que será la columna uno.
Al repasar caracter a caracter excluímos cualquier caracter numérico, esto es, nos quedamos solo con los caracteres de texto, espacios en blanco, comas, punto y coma, etc...
Que luego uniremos en una nueva cadena de texto única con UNIRCADENAS, para convertirlo finalmente con XMLFILTRO en un vector de paises...
Con lo que ya tendremos nuestra primera columna de la matriz final...
En el tercer paso obtendremos la parte numérica, esto serán las columnas de los años con los valores numéricos o vacíos.
Similar proceso al anterior, pero discriminando todos los caracteres de texto, pero respetando los espacios en blanco (que serán futuras columnas sin dato).
Revisa las entradas comentadas para entender mejor estos dos pasos:
Recuperar textos
Recuperar números
El siguiente paso consiste en unir los dos resultados previos (países más valores), para identificar a continuación el número de filas y columnas existentes (según los caracteres separadores incluidos):
Contamos el número de filas y columnas según el número de separadores (; para filas y \ para columnas) existentes...
Y una vez conocidos, convertimos todos los separadores en ;
El sentido de esto es disponer seguidamente de un único vector de todos los datos países, vacíos y valores, con una cadencia de distribución...
Así pues llegamos casi al final. Con la última sustitución realizada, aplicamos una alternativa a XMLFILTRO para separar elementos (siempre es bueno conocer otros métodos de trabajo):
Personalmente, y mientras Microsoft no libere alguna función tipo SPLIT, prefiero XMLFILTRO ;-)
El vector obtenido tendrá tantos elementos como el resultante de multiplicar filas por columnas, distribuidos de acuerdo a un patrón:
Datos de la primera fila completa, después datos de la segunda fila, etc...
El último paso de la fórmula se encarga de convertir un vector en matriz:
Para lo cual nos apoyamos en INDICE y en SECUENCIA para generar la matriz de distribución de filas por columnas.

Algo larga, pero con un buen resultado ;-)
En el artículo de hoy conseguiremos lo mismo pero solo con fórmulas!!
¿Cuántas veces hemos copiado o exportado datos de un pdf y nos ha devuelto la 'supuesta tabla' como una cadena de valores no respetando la dsitribución de columnas?... Muchas veces el problema es el cómo se generó esa tabla y se insertó en el documento y otras simplemente falla el OCR de lectura del pdf.
El caso es que lo que tenemos en nuestra hoja de cálculo es un rango de celdas, cada una con una cadena de texto con la secuencia de la columnas dispuestas seguidas... como vemos en la imagen anterior :'(
Veamos cómo con una 'formulita' conseguiremos convertir esas celdas en la matriz original esperada.
Lo primero es buscar patrones en esas celdas...
Observamos que hay en primer lugar, tanto para encabezados como para datos, una secuencia de palabras que queremos se conviertan en la primera columna.
Y el resto de datos, numéricos o vacíos, serán el resto de columnas (en mi ejemplo corresponderán a los tres años dispuestos).
Como puedes comprobar en la imagen la fórmula no es pequeña... no puede ser de otra forma, ya que el trabajo que realiza es complejo:
1- segrega la primera parte de textos (el PAÍS) independientemente de las palabras que contenga.
Puedes verificar en la imagen que hay paises escritos de distintas formas con 1,2,3, ... palabras
2- extrae las columnas de años respetando aquellas que no tengan valor.
3- unimos ambas para componer nuestra matriz final.
Te recomiendo para los dos primero puntos revises estas dos entradas del blog:
Recuperar textos
Recuperar números
Son técnicas que emplearemos en la fórmula siguiente:
=LET(cadena;UNIRCADENAS(";";FALSO;$I$3:$I$8);
k;SECUENCIA(LARGO(cadena));
titulos;LET(tratado1;LET(at;EXTRAE(cadena;k;1);
SI(CODIGO(at)<=57;SI(CODIGO(at)>=48;"";at);at) );
UNIRCADENAS("";VERDADERO;tratado1));
calculo1;XMLFILTRO("<i><d>"&SUSTITUIR(titulos;";";"</d><d>")&"</d></i>";"//d");
espaciosCab;LARGO(calculo1)-LARGO(SUSTITUIR(calculo1;" ";""));
numeros;LET(tratado2;LET(an;EXTRAE(cadena;k;1);
SI(CODIGO(an)>59;"";an) );
txt; (UNIRCADENAS("";VERDADERO;tratado2));
txt );
calculo2;XMLFILTRO("<i><d>"&SUSTITUIR(SUSTITUIR(numeros;" ";"\");";";"</d><d>")&"</d></i>";"//d");
cadenafinal;UNIRCADENAS(";";FALSO;calculo1&EXTRAE(calculo2;espaciosCab+1;LARGO(calculo2)));
filas; (LARGO(cadenafinal)-LARGO(SUSTITUIR(cadenafinal;";";"")))+1;
cols; ((LARGO(cadenafinal)-LARGO(SUSTITUIR(cadenafinal;"\";"")))/filas)+1;
elementos; SUSTITUIR(cadenafinal;"\";";");
separoElementos; LET(n; cols*filas; kf; SECUENCIA(n);
ini; SI.ERROR( ENCONTRAR("|";SUSTITUIR(elementos;";";"|";kf-1)) +1;1);
fin; SI.ERROR( ENCONTRAR("|";SUSTITUIR(elementos;";";"|";kf));LARGO(elementos)+1);
ESPACIOS(EXTRAE(elementos; ini; fin-ini)) );
textoMatriz; LET( matriz; SECUENCIA(filas;cols);
INDICE( separoElementos; matriz) );
textoMatriz)Analicemos nuestra fórmula por partes...
En primer lugar identificamos el rango de celdas y lo concatenamos con la función UNIRCADENAS, para a continuación realizar un conteo de caracteres total... necesario para posteriormente proceder a una extracción caracter a caracter:
=LET(cadena;UNIRCADENAS(";";FALSO;$I$3:$I$8);
k;SECUENCIA(LARGO(cadena))En segundo lugar recuperaremos, bajo cualquier condición (dará igual el número de palabras que tenga) la lista de paises, que será la columna uno.
titulos;LET(tratado1;LET(at;EXTRAE(cadena;k;1);
SI(CODIGO(at)<=57;SI(CODIGO(at)>=48;"";at);at) );
UNIRCADENAS("";VERDADERO;tratado1));
calculo1;XMLFILTRO("<i><d>"&SUSTITUIR(titulos;";";"</d><d>")&"</d></i>";"//d");
espaciosCab;LARGO(calculo1)-LARGO(SUSTITUIR(calculo1;" ";""))Al repasar caracter a caracter excluímos cualquier caracter numérico, esto es, nos quedamos solo con los caracteres de texto, espacios en blanco, comas, punto y coma, etc...
Que luego uniremos en una nueva cadena de texto única con UNIRCADENAS, para convertirlo finalmente con XMLFILTRO en un vector de paises...
Con lo que ya tendremos nuestra primera columna de la matriz final...
En el tercer paso obtendremos la parte numérica, esto serán las columnas de los años con los valores numéricos o vacíos.
numeros;LET(tratado2;LET(an;EXTRAE(cadena;k;1);
SI(CODIGO(an)>59;"";an) );
txt; (UNIRCADENAS("";VERDADERO;tratado2));
txt );
calculo2;XMLFILTRO("<i><d>"&SUSTITUIR(SUSTITUIR(numeros;" ";"\");";";"</d><d>")&"</d></i>";"//d")Similar proceso al anterior, pero discriminando todos los caracteres de texto, pero respetando los espacios en blanco (que serán futuras columnas sin dato).
Revisa las entradas comentadas para entender mejor estos dos pasos:
Recuperar textos
Recuperar números
El siguiente paso consiste en unir los dos resultados previos (países más valores), para identificar a continuación el número de filas y columnas existentes (según los caracteres separadores incluidos):
cadenafinal;UNIRCADENAS(";";FALSO;calculo1&EXTRAE(calculo2;espaciosCab+1;LARGO(calculo2)));
filas; (LARGO(cadenafinal)-LARGO(SUSTITUIR(cadenafinal;";";"")))+1;
cols; ((LARGO(cadenafinal)-LARGO(SUSTITUIR(cadenafinal;"\";"")))/filas)+1;
elementos; SUSTITUIR(cadenafinal;"\";";");Contamos el número de filas y columnas según el número de separadores (; para filas y \ para columnas) existentes...
Y una vez conocidos, convertimos todos los separadores en ;
El sentido de esto es disponer seguidamente de un único vector de todos los datos países, vacíos y valores, con una cadencia de distribución...
Así pues llegamos casi al final. Con la última sustitución realizada, aplicamos una alternativa a XMLFILTRO para separar elementos (siempre es bueno conocer otros métodos de trabajo):
separoElementos; LET(n; cols*filas; kf; SECUENCIA(n);
ini; SI.ERROR( ENCONTRAR("|";SUSTITUIR(elementos;";";"|";kf-1)) +1;1);
fin; SI.ERROR( ENCONTRAR("|";SUSTITUIR(elementos;";";"|";kf));LARGO(elementos)+1);
ESPACIOS(EXTRAE(elementos; ini; fin-ini)) )Personalmente, y mientras Microsoft no libere alguna función tipo SPLIT, prefiero XMLFILTRO ;-)
El vector obtenido tendrá tantos elementos como el resultante de multiplicar filas por columnas, distribuidos de acuerdo a un patrón:
Datos de la primera fila completa, después datos de la segunda fila, etc...
El último paso de la fórmula se encarga de convertir un vector en matriz:
textoMatriz; LET( matriz; SECUENCIA(filas;cols);
INDICE( separoElementos; matriz) );
textoMatrizPara lo cual nos apoyamos en INDICE y en SECUENCIA para generar la matriz de distribución de filas por columnas.
Algo larga, pero con un buen resultado ;-)


No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.