Toca en el día de hoy analizar el impacto de trabajar con Power Query sobre el tamaño de nuestros ficheros (y su consecuente ralentización).
Partiremos de un fichero .csv con datos inventados de diferentes países por meses, con un total de 380.160 registros.
El peso inicial de este archivo .csv: 29.442 Kb.
Así pues, nuestro primer paso será abrir un libro de Excel (.xlsx) y cargar los datos a una consulta de Power Query.
Desde la Ficha Datos > grupo Obtener y transformar > Obtener datos > Desde un archivo > Desde texto/csv
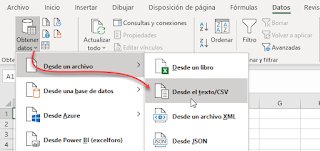
Indicaremos la ruta de nuestro fichero .csv y en un primer término simplemente Cargaremos y cerraremos en una Tabla

Es decir, en este primer experimento no hay tratamiento o transformación de datos.
Tras esperar a la actualización y comprobar que se han cargado las 380.160 filas, procedemos a guardar nuestro libro y comprobar el peso de este... que es de 29.512 Kb.
Unos bytes por encima del peso original del fichero .csv.
Poco esperanzador :-(
Vamos a por una alternativa... Cargaremos y cerraremos en modo Tabla dinámica

Esperamos a que la consulta actualice sus 380.160 filas y guardamos el fichero.
Ahora su tamaño ha bajado a 10.613 Kb (más o menos un tercio del tamaño original!!) :O
En este caso, al devolver la info a través de un informe de tabla dinámica, y por tanto, no tener la info 'repetida' en la vista de hoja de cálulo, el peso del fichero es sustancialmente menor.
Otra variante asombrosa sería Cargar y cerrar en Solo conexión...
Dejando en esta situación, solo conexión, un peso del fichero de 16 Kb !!!!.
Disponible para combinar con otras posibles consultas si fuera necesario.
En estos casos descritos no ha habido transformación alguna de columnas o filas.. ¿pero que pasaría si Quitamos columnas innecesarias de nuestra consulta??.
Veamos que ocurre si eliminamos algunas columnas (hasta 9 de las 15 existentes en el .csv original).
Tras eliminar dichas columnas volvemos a Cargar y cerrar en modo Tabla, y verificar que se han actualizado las 380.160 filas, guardamos de nuevo el libro de trabajo y comprobamos que su peso es de 10.430 kB
Recuerda que el peso del fichero, con todas sus columnas y filas cargadas y mostradas en una Tabla (primera prueba realizada) era de 29.512 Kb; es decir, eliminando columnas reducimos peso... en mi ejemplo de 29.512 a 10.430.
Si en lugar de cargar y cerrar en una tabla, lo mostramos en un informe de tabla dinámica con las columnas ya eliminadas, comprobaremos que el peso queda en unos 3.827 Kb.
Con todas sus columnas, el equivalente, tenía 10.613 kb. Una bajada de +/- 7 Mb
Continuamos ahora rebajando el número de filas aplicando algún filtro sobre un campo de años
Asi pues, con todas sus columnas de origen y mostrada la consulta sobre una Tabla en la hoja de cálculo, aplicamos un criterio sobre la columna de año para mostrar solo años posteriores a 1975 (los datos originales eran de 1900 a 2019).
Se nos quedan por tanto las 15 columnas originales pero solo con 142.560 filas...
y un tamaño del fichero (frente a los 29.512 Kb) de 11.046 Kb... de nuevo casi un tercio.
Si quitamos columnas, además del filtro de años aplicado, el peso sería de 3.969 Kb.
Puedes comprobar cuantas combinaciones se te ocurran... quitar columnas o aplicar filtros mostrando los datos como Tabla, Informe de tabla dinámica o Solo conexión, pero la conclusión será siempre la misma:
Lo primero que debemos hacer con nuestras consultas es eliminar columnas innecesarias y aplicar los filtros oportunos que muestren información realmente relevante.
Solo una vez hecho esto, podremos decidir en qué forma (Tabla, Tabla dinámica o Conexión solo) mostrar dicha información... según nuestras necesidades.
Una última variable, nada despreciable, aparece con Power Pivot y su Modelo de datos.
Cuando nuestra meta es claramente trabajar con un informe de tablas dinámicas, lo recomendable será realizar todo tipos de cálculos, modificaciones, transformaciones (como las ya comentadas, entre otras) con el Editor de Power Query, para una vez concluido el proceso Cargar y cerrar como Solo conexión pero Agregándolo al modelo de datos

Posteriormente deberemos entrar en el Administrador de Power Pivot e insertar una Tabla dinámica desde el modelo de datos...
Esto reducirá aún más el peso del fichero, y además agilizará los procesos de cálculo de nuestro libro.
Otras recomendaciones variadas... (adicionales a las anteriores):
- Si trabajas con el Modelo de datos de Power Pivot crea Medidas mejor que Columnas calculadas
- Siempre mejor, si es inevitable, calcular columnas en Power Query que en Power Pivot
/ - Mejor Campo calculado en la tabla dinámica que como Medida en el modelo
- Si existen columnas del tipo DateTime mejor separalas en dos columnas, una solo Date, otra con Time
- Cuando sea posible redondea las columnas (evita decimales 'interminables')
Todos estos puntos, y alguno más, facilitarán que tus procesos sobre grandes bases de datos sean agiles y rápidos en sus cálculos...
Espero algo de lo expuesto te sea de utilidad...
Partiremos de un fichero .csv con datos inventados de diferentes países por meses, con un total de 380.160 registros.
El peso inicial de este archivo .csv: 29.442 Kb.
Así pues, nuestro primer paso será abrir un libro de Excel (.xlsx) y cargar los datos a una consulta de Power Query.
Desde la Ficha Datos > grupo Obtener y transformar > Obtener datos > Desde un archivo > Desde texto/csv

Indicaremos la ruta de nuestro fichero .csv y en un primer término simplemente Cargaremos y cerraremos en una Tabla

Es decir, en este primer experimento no hay tratamiento o transformación de datos.
Tras esperar a la actualización y comprobar que se han cargado las 380.160 filas, procedemos a guardar nuestro libro y comprobar el peso de este... que es de 29.512 Kb.
Unos bytes por encima del peso original del fichero .csv.
Poco esperanzador :-(
Vamos a por una alternativa... Cargaremos y cerraremos en modo Tabla dinámica

Esperamos a que la consulta actualice sus 380.160 filas y guardamos el fichero.
Ahora su tamaño ha bajado a 10.613 Kb (más o menos un tercio del tamaño original!!) :O
En este caso, al devolver la info a través de un informe de tabla dinámica, y por tanto, no tener la info 'repetida' en la vista de hoja de cálulo, el peso del fichero es sustancialmente menor.
Otra variante asombrosa sería Cargar y cerrar en Solo conexión...
Dejando en esta situación, solo conexión, un peso del fichero de 16 Kb !!!!.
Disponible para combinar con otras posibles consultas si fuera necesario.
En estos casos descritos no ha habido transformación alguna de columnas o filas.. ¿pero que pasaría si Quitamos columnas innecesarias de nuestra consulta??.
Veamos que ocurre si eliminamos algunas columnas (hasta 9 de las 15 existentes en el .csv original).
Tras eliminar dichas columnas volvemos a Cargar y cerrar en modo Tabla, y verificar que se han actualizado las 380.160 filas, guardamos de nuevo el libro de trabajo y comprobamos que su peso es de 10.430 kB
Recuerda que el peso del fichero, con todas sus columnas y filas cargadas y mostradas en una Tabla (primera prueba realizada) era de 29.512 Kb; es decir, eliminando columnas reducimos peso... en mi ejemplo de 29.512 a 10.430.
Si en lugar de cargar y cerrar en una tabla, lo mostramos en un informe de tabla dinámica con las columnas ya eliminadas, comprobaremos que el peso queda en unos 3.827 Kb.
Con todas sus columnas, el equivalente, tenía 10.613 kb. Una bajada de +/- 7 Mb
Continuamos ahora rebajando el número de filas aplicando algún filtro sobre un campo de años
Asi pues, con todas sus columnas de origen y mostrada la consulta sobre una Tabla en la hoja de cálculo, aplicamos un criterio sobre la columna de año para mostrar solo años posteriores a 1975 (los datos originales eran de 1900 a 2019).
Se nos quedan por tanto las 15 columnas originales pero solo con 142.560 filas...
y un tamaño del fichero (frente a los 29.512 Kb) de 11.046 Kb... de nuevo casi un tercio.
Si quitamos columnas, además del filtro de años aplicado, el peso sería de 3.969 Kb.
Puedes comprobar cuantas combinaciones se te ocurran... quitar columnas o aplicar filtros mostrando los datos como Tabla, Informe de tabla dinámica o Solo conexión, pero la conclusión será siempre la misma:
Lo primero que debemos hacer con nuestras consultas es eliminar columnas innecesarias y aplicar los filtros oportunos que muestren información realmente relevante.
Solo una vez hecho esto, podremos decidir en qué forma (Tabla, Tabla dinámica o Conexión solo) mostrar dicha información... según nuestras necesidades.
Una última variable, nada despreciable, aparece con Power Pivot y su Modelo de datos.
Cuando nuestra meta es claramente trabajar con un informe de tablas dinámicas, lo recomendable será realizar todo tipos de cálculos, modificaciones, transformaciones (como las ya comentadas, entre otras) con el Editor de Power Query, para una vez concluido el proceso Cargar y cerrar como Solo conexión pero Agregándolo al modelo de datos

Posteriormente deberemos entrar en el Administrador de Power Pivot e insertar una Tabla dinámica desde el modelo de datos...
Esto reducirá aún más el peso del fichero, y además agilizará los procesos de cálculo de nuestro libro.
Otras recomendaciones variadas... (adicionales a las anteriores):
- Si trabajas con el Modelo de datos de Power Pivot crea Medidas mejor que Columnas calculadas
- Siempre mejor, si es inevitable, calcular columnas en Power Query que en Power Pivot
/ - Mejor Campo calculado en la tabla dinámica que como Medida en el modelo
- Si existen columnas del tipo DateTime mejor separalas en dos columnas, una solo Date, otra con Time
- Cuando sea posible redondea las columnas (evita decimales 'interminables')
Todos estos puntos, y alguno más, facilitarán que tus procesos sobre grandes bases de datos sean agiles y rápidos en sus cálculos...
Espero algo de lo expuesto te sea de utilidad...


No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.