Llevo algunos días dando vueltas a la decisión de publicar o no este artículo...
La duda viene por lo largo de la formulación, y por que no tengo claro que sea la opción más óptima de lograrlo (abro hilo de sugerencias) ;-)
El ejercicio consiste en identificar el mayor rango sin datos de un listado, donde nos encontramos con ciertas filas marcadas que delimitan los diferentes huecos de celdas buscadas... pero solo la mayor de ellas es la que nos interesa.
Veamos un ejemplo en la imagen siguiente:

Como se observa en la imagen anterior existen varios 'huecos', filas sin marcas... pero solo hay una de ellas, el primer rango, con el mayor número de celdas no marcadas (filas 5,6 y 7).
Salvo mejor interpretación, mi opción ha sido emplear funciones como LAMBDA, LET, MAP, SCAN o clásicas como MODA, MEDIANA, PROMEDIO o SUMAPRODUCTO.
Explicaré la idea general del cálculo...
Tras diferentes pruebas, comprobé que cierto cálculo acumulado respecto de la diferencia de 'media' y 'mediana' sobre el rango de análisis, determinaba unos valores coincidentes precisamente para el rango buscado, esto es, era el valor repetido que más se repetía (concepto de MODA en términos estadísticos).
Aunque bajo ciertas combinaciones de filas marcadas, ese valor más repetido se dispersaba... pero por suerte, con una doble combinación empleando para el cálculo de diferencias tanto la media como el promedio, conseguí discriminar esos valores o filas atípicas.
Te recomiendo, si es de tu interés, descompongas por variables, las fórmulas que voy a detallar a continuación.
En primer lugar construiremos, con una función LAMBDA a incluir en el administrador de nombres definidos, para el cálculo de diferencias acumuladas respecto de la media; la llamaré 'lmbMEDIA', y requiere dos argumentos, que serán cada uno de los campos de marcas de nuestra tabla.
La función formulada:
La siguiente función LAMBDA ('lmbMEDIANA') también requiere dos argumentos, que serán cada uno de los campos de marcas de nuestra tabla.. y es idéntica a la anterior, pero operando no sobre la media, sino por la MEDIANA:
Como ves son idénticas en el proceso... Lo que nos devolverían sobre el ejemplo anterior:

Verificamos como ambas funciones devuelven vectores de valores donde el mayor número de repeticiones coincide con el rango buscado...
Nos queda una última fórmula que nos retorne el rango, a partir de los resultados de nuestras funciones LAMBDA.
En esta última fórmula comparo los resultados de los vectores obtenidos con las funciones LAMBDA con sus MODA (con el fin de identificar el valor más repetido... y por tanto el rango de mayor tamaño).
Después simplemente corrijo el nuevo vector para concluir con el resultado de filas que corresponden al rango de mayor tamaño sin datos...
Espero te resulte interesante y no demasiado retorcido ;-)
La duda viene por lo largo de la formulación, y por que no tengo claro que sea la opción más óptima de lograrlo (abro hilo de sugerencias) ;-)
El ejercicio consiste en identificar el mayor rango sin datos de un listado, donde nos encontramos con ciertas filas marcadas que delimitan los diferentes huecos de celdas buscadas... pero solo la mayor de ellas es la que nos interesa.
Veamos un ejemplo en la imagen siguiente:

Como se observa en la imagen anterior existen varios 'huecos', filas sin marcas... pero solo hay una de ellas, el primer rango, con el mayor número de celdas no marcadas (filas 5,6 y 7).
Salvo mejor interpretación, mi opción ha sido emplear funciones como LAMBDA, LET, MAP, SCAN o clásicas como MODA, MEDIANA, PROMEDIO o SUMAPRODUCTO.
Explicaré la idea general del cálculo...
Tras diferentes pruebas, comprobé que cierto cálculo acumulado respecto de la diferencia de 'media' y 'mediana' sobre el rango de análisis, determinaba unos valores coincidentes precisamente para el rango buscado, esto es, era el valor repetido que más se repetía (concepto de MODA en términos estadísticos).
Aunque bajo ciertas combinaciones de filas marcadas, ese valor más repetido se dispersaba... pero por suerte, con una doble combinación empleando para el cálculo de diferencias tanto la media como el promedio, conseguí discriminar esos valores o filas atípicas.
Te recomiendo, si es de tu interés, descompongas por variables, las fórmulas que voy a detallar a continuación.
En primer lugar construiremos, con una función LAMBDA a incluir en el administrador de nombres definidos, para el cálculo de diferencias acumuladas respecto de la media; la llamaré 'lmbMEDIA', y requiere dos argumentos, que serán cada uno de los campos de marcas de nuestra tabla.
La función formulada:
=LAMBDA(marca_1;marca_2;
LET(marca1;marca_1; marca2;marca_2;
arrPPAL;MAP(marca1;marca2;
LAMBDA(mrA;mrB;SI(O(mrA<>"";mrB<>"");FILA(mrA);"")));
Media_;PROMEDIO(arrPPAL);
antesMedia;SUMAPRODUCTO(--((arrPPAL<=Media_)*(arrPPAL<>"")));
despuesMedia;SUMAPRODUCTO(--((arrPPAL>Media_)*(arrPPAL<>"")));
dif_1Media;antesMedia-despuesMedia-1;
difMedia;antesMedia-despuesMedia;
rngModMedia_1;SI.ERROR(MAP(arrPPAL;LAMBDA(x;x+dif_1Media));"");
rngModMedia;SI.ERROR(MAP(arrPPAL;LAMBDA(x;x+difMedia));"");
CalcMedia;PROMEDIO(rngModMedia);
CalculoMedia;SCAN(0;SI.ERROR(MAP(rngModMedia_1;LAMBDA(x;x-CalcMedia));0);LAMBDA(a;b;a+b));
CalculoMedia))La siguiente función LAMBDA ('lmbMEDIANA') también requiere dos argumentos, que serán cada uno de los campos de marcas de nuestra tabla.. y es idéntica a la anterior, pero operando no sobre la media, sino por la MEDIANA:
=LAMBDA(marca_1;marca_2;
LET(marca1;marca_1; marca2;marca_2;
arrPPAL;MAP(marca1;marca2;
LAMBDA(mrA;mrB;SI(O(mrA<>"";mrB<>"");FILA(mrA);""))); mediana_;MEDIANA(arrPPAL);
antesMediana;SUMAPRODUCTO(--((arrPPAL<=mediana_)*(arrPPAL<>"")));
despuesMediana;SUMAPRODUCTO(--((arrPPAL>mediana_)*(arrPPAL<>"")));
dif_1Mediana;antesMediana-despuesMediana-1;
difMediana;antesMediana-despuesMediana;
rngModMediana_1;SI.ERROR(MAP(arrPPAL;LAMBDA(x;x+dif_1Mediana));"");
rngModMediana;SI.ERROR(MAP(arrPPAL;LAMBDA(x;x+difMediana));"");
CalcMediana;MEDIANA(rngModMediana);
CalculoMediana;SCAN(0;SI.ERROR(MAP(rngModMediana_1;LAMBDA(x;x-CalcMediana));0);LAMBDA(a;b;a+b));
CalculoMediana))Como ves son idénticas en el proceso... Lo que nos devolverían sobre el ejemplo anterior:

Verificamos como ambas funciones devuelven vectores de valores donde el mayor número de repeticiones coincide con el rango buscado...
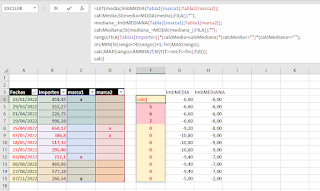
Nos queda una última fórmula que nos retorne el rango, a partir de los resultados de nuestras funciones LAMBDA.
=LET(media;lmbMEDIA(Tabla1[marca1];Tabla1[marca2]); calcMedia;SI(media=MODA(media);FILA();""); mediana_;lmbMEDIANA(Tabla1[marca1];Tabla1[marca2]); calcMediana;SI(mediana_=MODA(mediana_);FILA();""); rango;FILA(Tabla1[Importes])*(calcMedia=calcMediana)*(calcMedia<>"")*(calcMediana<>""); ini;MIN(SI(rango<>0;rango))+1; fin;MAX(rango); calc;MAP(rango;LAMBDA(f;SI(Y(f>=ini;f<=fin);f;0))); calc)

En esta última fórmula comparo los resultados de los vectores obtenidos con las funciones LAMBDA con sus MODA (con el fin de identificar el valor más repetido... y por tanto el rango de mayor tamaño).
Después simplemente corrijo el nuevo vector para concluir con el resultado de filas que corresponden al rango de mayor tamaño sin datos...
Espero te resulte interesante y no demasiado retorcido ;-)


No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.