Un problema frecuente con el que nos encontramos al intentar cruzar diferentes tablas, es que al utilizar funciones del tipo NATURALINNERJOIN, nos devuelve mensajes de error del tipo: 'No encontrados campos comunes'.
Veamos, a partir del caso del artículo anterior un ejemplo y su solución.
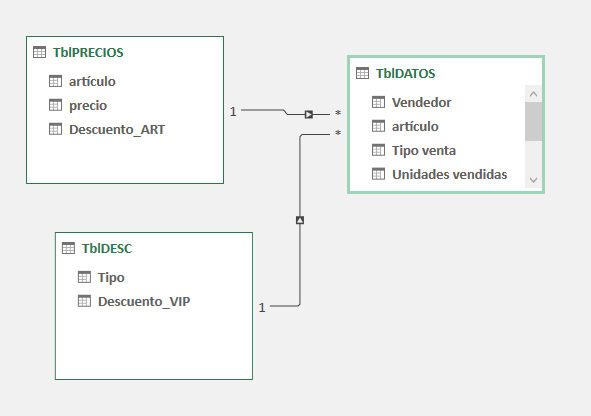
Tenemos un supuesto donde combinaremos datos de una tabla 'real' con otra 'estática', donde cruzaremos ambas con la función NATURALINNERJOIN, la cual nos dará un problema incomprensible:
Indicará que no encuentre campos en común... a pesar de que estemos viendo los campos en las dos tablaas con exactamente el mismo nombre.
Aquí el problema no es, en realidad, el nombre del campo... si no que DAX no identifica el mismo tipo de datos en ambas columnas (aunque sí lo tenga :( ).
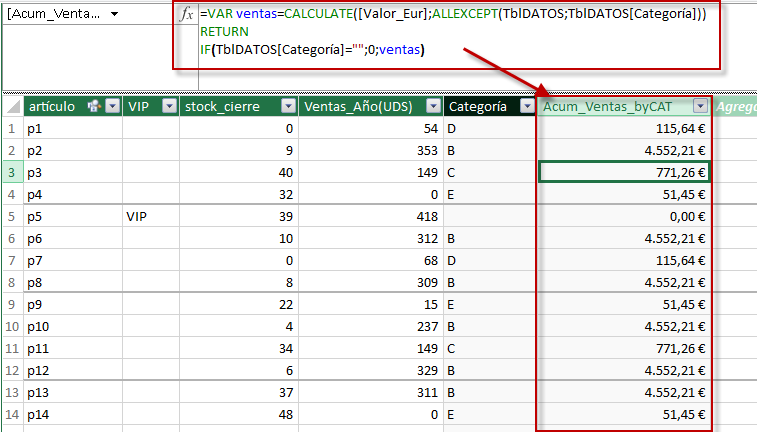
El truco-solución será, algo trabajado, emplear SELECTCOLUMNS para recuperar las columnas necesarias, lo que nos permitirá homogeneizar tanto el nombre de las columnas (por si hubiera alguna pega), como el tipo de datos.
¿cómo?, añadiendo un +0 si el tipo es numérico (INTEGER, DECIMAL, CURRENCY o DOUBLE), y añadiendo un &"" si fuera STRING.
Fíjate en el código siguiente:

Nota el detalle en ambas variables:
"Vendedor";[Vendedor]&"";
"Uds"; [Unidades vendidas]+0
"Tarifa"; [Tarifa]+0
Esta 'sencilla' acción permite el reconocimiento, por parte de NATURALINNERJOIN de los campos comunes... y el éxito de nuestro trabajo!!!.
Veamos, a partir del caso del artículo anterior un ejemplo y su solución.
Tenemos un supuesto donde combinaremos datos de una tabla 'real' con otra 'estática', donde cruzaremos ambas con la función NATURALINNERJOIN, la cual nos dará un problema incomprensible:
Indicará que no encuentre campos en común... a pesar de que estemos viendo los campos en las dos tablaas con exactamente el mismo nombre.
Aquí el problema no es, en realidad, el nombre del campo... si no que DAX no identifica el mismo tipo de datos en ambas columnas (aunque sí lo tenga :( ).
El truco-solución será, algo trabajado, emplear SELECTCOLUMNS para recuperar las columnas necesarias, lo que nos permitirá homogeneizar tanto el nombre de las columnas (por si hubiera alguna pega), como el tipo de datos.
¿cómo?, añadiendo un +0 si el tipo es numérico (INTEGER, DECIMAL, CURRENCY o DOUBLE), y añadiendo un &"" si fuera STRING.
Fíjate en el código siguiente:
TablaEstatica:=VAR tblTIPO=SELECTCOLUMNS(DATATABLE("Vendedor";STRING;"Tarifa";DOUBLE;
{{"JUAN";100};{"EVA";150};{"BEA";200}} );
"Vendedor";[Vendedor]&"";
"Tarifa"; [Tarifa]+0)
VAR TblJUAN_P2=SELECTCOLUMNS(FILTER(TblDATOS;TblDATOS[Tipo venta]="VIP" && TblDATOS[artículo]="p2");
"Vendedor";[Vendedor]&"";
"Uds"; [Unidades vendidas]+0)
VAR CRUCE=NATURALINNERJOIN(TblJUAN_P2;tblTIPO)
VAR calculo=SUMX(CRUCE;[Uds]*[Tarifa])
RETURN
calculo
Nota el detalle en ambas variables:
"Vendedor";[Vendedor]&"";
"Uds"; [Unidades vendidas]+0
"Tarifa"; [Tarifa]+0
Esta 'sencilla' acción permite el reconocimiento, por parte de NATURALINNERJOIN de los campos comunes... y el éxito de nuestro trabajo!!!.