Hoy analizaremos dos alternativas para segmentar con Power Query grandes volúmenes de información.
Todos los que usamos Power Query en mayor o menor medida hemos leído sobre las bondades de 'filtrar' nuestras filas al inicio de nuestros procesos para reducir los tiempos de ejecución en pasos siguientes... Habitualmente lo conseguimos con la acción de filtrado sobre ciertas columnas, o lo que es lo mismo, empleado la función M : Table.SelectRows, conocida y usada en multitud de ejemplos...
Pero hay más alternativas (y no necesariamente mejores):
Table.Partition(table as table, column as text, groups as number, hash as function) as list
función que nos devuelve una Lista de tablas segmentadas, cada una de las cuales recoge un número indeterminado de filas, pudiendo controlar, en todo caso, qué filas incluimos en cada una.
Sin embargo la forma de 'separar' la información en distintas tablas es un tanto peculiar... ya que la función nos pide trabajar sobre una única columna!! (¿nos olvidamos de segmentar por varias columnas??... espera un poco y sigue leyendo).
Además el cuarto argumento de la función nos pide una función HASH (o función 'resumen'), que basicamente significa que de alguna manera debe trabajar sobre valores numéricos!?.
Si leemos la ayuda? de la documentación de Microsoft nos dice:
'Divide la tabla en una lista de grupos, es decir, en cierto número de tablas, basándose en una función hash y en el valor de la columna de cada fila. La función hash se aplica al valor de columna de una fila para obtener un valor hash para esta última. El valor "groups" del módulo hash determina en qué tablas devueltas se colocará la fila.'
Bastante confuso...
Veamos un ejemplo... supongamos una base de datos (d enombre 'compras4') con 215.000 registros y tres campos: artículo, país y número de unidades.
Queremos obtener una partición únicamente con los artículos 'a'.
Si cargamos dicha tabla a nuestro editor de Power Query, y sobre la consulta creada generamos una segunda consulta como referencia de la primera, tendríamos como único movimiento:
donde indicamos que trabajamos sobre la tabla completa 'compras4' (con 215.000 filas), en concreto sobre la columna llamada 'art', que esperamos obtener dos particiones (i.e., dos tablas), la primera de ellas con las coincidencias del artículo 'a'.
Nota lo retorcido de la función Hash empleada... donde con algú tipo de fórmula o función tenemos que construir la equivalencia de los códigos 'a' y asociarlo a un valor numérico.
Igualmente importante es que el valor numérico asociado/calculado debe estar ordenado en ascendente, ya que la lista de tablas obtenidas con la función respetará esa ordenación.
Es decir, en mi ejemplo, con el condicional estoy asignado el valor cero a los artículos 'a' y el valor 1 al resto...
por tanto, primero irá la tabla con valor cero (la correspondiente a los artículos 'a'), y la segunda tabla generada el resto de valores asociados al valor numérico uno.

La consecuente pregunta es.. si esta función nos pide trabajar exclusivamente sobre el nombre de una columna, ¿cómo puedo aplicar una partición sobre un criterio multicolumna?.
He buscado por internet y no he encontrado nada al respecto... asi que probé algunas 'cosillas' y di con una solución intermedia:
donde se alimenta el primer argumento con una tabla intermedia al que hemos añadido una nueva columna resultante de concatenar los valores de las columnas sobre las que trabajar (había que salir del paso... y el caso dió resultado).
Esa tabla intermedia, con la nueva columna será la base sobre la que aplicar la función Hash del ejemplo anterior...

Este sistema o forma de convertir textos a números, aunque un poco arcáico, es operativo.. permitiendo además obtener listados mayores 'controlados' de tablas.
Por ejemplo si queremos obtener una partición de tres tablas:
1-la primera para los artículos 'a'
2-la segunda para los artículos 'c'
3-para el resto de artículos
Nuesta consulta podría tener la siguiente forma:
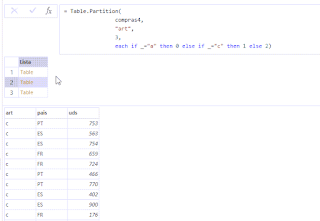
Fíjate de nuevo en los valores asociados con el if then else a cada código de artículo.
Finalizar comentando que esta función Table.Partition es algo más lenta que la clásica Table.SelectRows !!.
En distintas pruebas, comparando una con otra obtenemos estos tiempos en milisegundos (para los 215.000 registros):
- FiltroMultiple con SelectRows //Total 96 ms
- ParticionMultiple con Partition //Total 132 ms
- FiltroSimple con SelectRows //Total 436 ms
- ParticionSimple con Partition //Total 415 ms
- FiltroMultipleSC //Total 73 ms
- ParticionMultipleSC //Total 100 ms
Concluir que, parece ser más óptimo en tiempo la clásica Table.SelectRows... pero no olvidar Table.Partition para tener alternativas ;-)
Todos los que usamos Power Query en mayor o menor medida hemos leído sobre las bondades de 'filtrar' nuestras filas al inicio de nuestros procesos para reducir los tiempos de ejecución en pasos siguientes... Habitualmente lo conseguimos con la acción de filtrado sobre ciertas columnas, o lo que es lo mismo, empleado la función M : Table.SelectRows, conocida y usada en multitud de ejemplos...
Pero hay más alternativas (y no necesariamente mejores):
Table.Partition(table as table, column as text, groups as number, hash as function) as list
función que nos devuelve una Lista de tablas segmentadas, cada una de las cuales recoge un número indeterminado de filas, pudiendo controlar, en todo caso, qué filas incluimos en cada una.
Sin embargo la forma de 'separar' la información en distintas tablas es un tanto peculiar... ya que la función nos pide trabajar sobre una única columna!! (¿nos olvidamos de segmentar por varias columnas??... espera un poco y sigue leyendo).
Además el cuarto argumento de la función nos pide una función HASH (o función 'resumen'), que basicamente significa que de alguna manera debe trabajar sobre valores numéricos!?.
Si leemos la ayuda? de la documentación de Microsoft nos dice:
'Divide la tabla en una lista de grupos, es decir, en cierto número de tablas, basándose en una función hash y en el valor de la columna de cada fila. La función hash se aplica al valor de columna de una fila para obtener un valor hash para esta última. El valor "groups" del módulo hash determina en qué tablas devueltas se colocará la fila.'
Bastante confuso...
Veamos un ejemplo... supongamos una base de datos (d enombre 'compras4') con 215.000 registros y tres campos: artículo, país y número de unidades.
Queremos obtener una partición únicamente con los artículos 'a'.
Si cargamos dicha tabla a nuestro editor de Power Query, y sobre la consulta creada generamos una segunda consulta como referencia de la primera, tendríamos como único movimiento:
let
Origen = Table.Partition(compras4,"art",2, each if _="a" then 0 else 1)
in
Origendonde indicamos que trabajamos sobre la tabla completa 'compras4' (con 215.000 filas), en concreto sobre la columna llamada 'art', que esperamos obtener dos particiones (i.e., dos tablas), la primera de ellas con las coincidencias del artículo 'a'.
Nota lo retorcido de la función Hash empleada... donde con algú tipo de fórmula o función tenemos que construir la equivalencia de los códigos 'a' y asociarlo a un valor numérico.
Igualmente importante es que el valor numérico asociado/calculado debe estar ordenado en ascendente, ya que la lista de tablas obtenidas con la función respetará esa ordenación.
Es decir, en mi ejemplo, con el condicional estoy asignado el valor cero a los artículos 'a' y el valor 1 al resto...
por tanto, primero irá la tabla con valor cero (la correspondiente a los artículos 'a'), y la segunda tabla generada el resto de valores asociados al valor numérico uno.
La consecuente pregunta es.. si esta función nos pide trabajar exclusivamente sobre el nombre de una columna, ¿cómo puedo aplicar una partición sobre un criterio multicolumna?.
He buscado por internet y no he encontrado nada al respecto... asi que probé algunas 'cosillas' y di con una solución intermedia:
let
Origen = Table.Partition(
Table.AddColumn(compras4,"combi", each [art]&[pais]),
"combi",
2,
each if _="aES" then 0 else 1)
in
Origendonde se alimenta el primer argumento con una tabla intermedia al que hemos añadido una nueva columna resultante de concatenar los valores de las columnas sobre las que trabajar (había que salir del paso... y el caso dió resultado).
Esa tabla intermedia, con la nueva columna será la base sobre la que aplicar la función Hash del ejemplo anterior...
Este sistema o forma de convertir textos a números, aunque un poco arcáico, es operativo.. permitiendo además obtener listados mayores 'controlados' de tablas.
Por ejemplo si queremos obtener una partición de tres tablas:
1-la primera para los artículos 'a'
2-la segunda para los artículos 'c'
3-para el resto de artículos
Nuesta consulta podría tener la siguiente forma:
let
Origen = Table.Partition(
compras4,
"art",
3,
each if _="a" then 0 else if _="c" then 1 else 2)
in
OrigenFíjate de nuevo en los valores asociados con el if then else a cada código de artículo.
Finalizar comentando que esta función Table.Partition es algo más lenta que la clásica Table.SelectRows !!.
En distintas pruebas, comparando una con otra obtenemos estos tiempos en milisegundos (para los 215.000 registros):
- FiltroMultiple con SelectRows //Total 96 ms
- ParticionMultiple con Partition //Total 132 ms
- FiltroSimple con SelectRows //Total 436 ms
- ParticionSimple con Partition //Total 415 ms
- FiltroMultipleSC //Total 73 ms
- ParticionMultipleSC //Total 100 ms
Concluir que, parece ser más óptimo en tiempo la clásica Table.SelectRows... pero no olvidar Table.Partition para tener alternativas ;-)


No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.