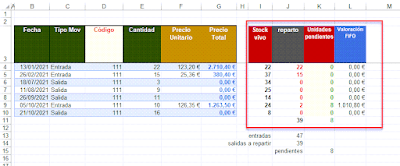
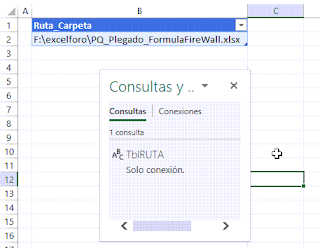
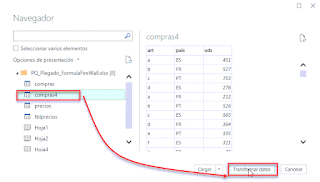
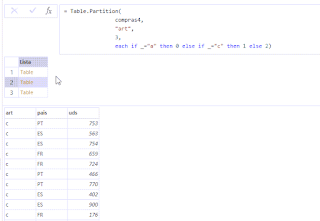
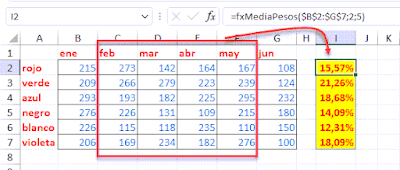
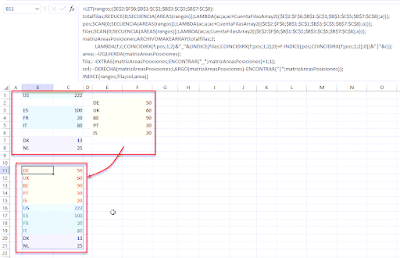
Se me presentó hace unos días una situación interesante... generar en una única matriz un resumen que indicara un conteo de empleados únicos, a partir de un listado de nombres.
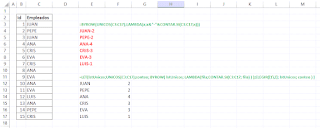
El objetivo es, por tanto, obtener una sola matriz con un listado de empleados únicos con el dato de conteo a su lado, i.e., con el número de veces que aparezca en el listado original.
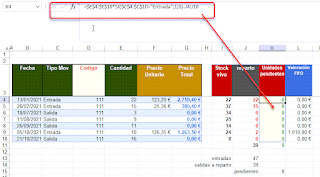
Mi primer intento fue con BYROW, en E4 añadimos:
=BYROW(UNICOS(C3:C17);LAMBDA(x;x&"-"&CONTAR.SI(C3:C17;x)))
donde alimentamos el argumento 'matriz' con el listado de empleados UNICOS, para posteriormente recorrer cada uno de estos trabajadores y obtener con LAMBDA un conteo directo (con CONTAR.SI)... además, concatenamos el resultado del conteo con el nombre del empleado.
Obtenemos un vecto único de resultados concatenados... No me gustaba mucho y le dí otra vuelta.
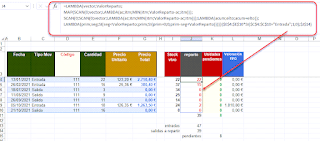
Recordé el 'viejo truco' para juntar vectores en una sola y única matriz empleando la función ELEGIR... asi que en la celda E12 apoyándonos en LET escribimos:
=LET(lstUnicos;UNICOS(C3:C17);
conteo; BYROW( lstUnicos; LAMBDA(fila;CONTAR.SI(C3:C17; fila) ) );
ELEGIR({1\2}; lstUnicos; conteo ) )
comenzamos asignando valor a dos variables:
- lstUnicos: que será el vector resultado devuelto por la función UNICOS, es decir, listado de empleados únicos
- conteo: la base de la fórmula primigénia con BYROW, es decir, un vector de conteos para cada empleado
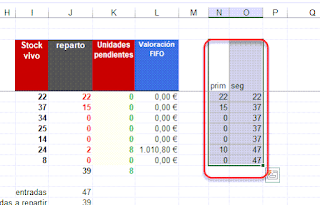
Acabamos uniendo los dos vectores en una sola matriz con ELEGIR.
Una última alternativa propuesta por mi colega Sergei Baklan (MVP Excel) sería:
=LET(u; UNICOS(C3:C17); countUnique; BYROW( u; LAMBDA(r; CONTAR.SI(C3:C17; r) ) ); SI({1\0}; u; countUnique ) )
donde aporta una curiosa alternativa a ELEGIR.
Un potente ejemplo de lo que podemos conseguir con estas nuevas funciones LAMBDA, LET, BYROW, etc...!!
El objetivo es, por tanto, obtener una sola matriz con un listado de empleados únicos con el dato de conteo a su lado, i.e., con el número de veces que aparezca en el listado original.
Mi primer intento fue con BYROW, en E4 añadimos:
=BYROW(UNICOS(C3:C17);LAMBDA(x;x&"-"&CONTAR.SI(C3:C17;x)))
donde alimentamos el argumento 'matriz' con el listado de empleados UNICOS, para posteriormente recorrer cada uno de estos trabajadores y obtener con LAMBDA un conteo directo (con CONTAR.SI)... además, concatenamos el resultado del conteo con el nombre del empleado.
Obtenemos un vecto único de resultados concatenados... No me gustaba mucho y le dí otra vuelta.
Recordé el 'viejo truco' para juntar vectores en una sola y única matriz empleando la función ELEGIR... asi que en la celda E12 apoyándonos en LET escribimos:
=LET(lstUnicos;UNICOS(C3:C17);
conteo; BYROW( lstUnicos; LAMBDA(fila;CONTAR.SI(C3:C17; fila) ) );
ELEGIR({1\2}; lstUnicos; conteo ) )
comenzamos asignando valor a dos variables:
- lstUnicos: que será el vector resultado devuelto por la función UNICOS, es decir, listado de empleados únicos
- conteo: la base de la fórmula primigénia con BYROW, es decir, un vector de conteos para cada empleado
Acabamos uniendo los dos vectores en una sola matriz con ELEGIR.
Una última alternativa propuesta por mi colega Sergei Baklan (MVP Excel) sería:
=LET(u; UNICOS(C3:C17); countUnique; BYROW( u; LAMBDA(r; CONTAR.SI(C3:C17; r) ) ); SI({1\0}; u; countUnique ) )
donde aporta una curiosa alternativa a ELEGIR.
Un potente ejemplo de lo que podemos conseguir con estas nuevas funciones LAMBDA, LET, BYROW, etc...!!