Dicen que no hay dos sin tres.. y en este caso cerraré mi triángulo favorito: VBA-fórmulas-Power Query replicando los algoritmos que nos permitieros extraer o eliminar subcadenas de texto (revisa la entrada que hablamos de VbScript.RegExp y la que expuse con igual solución empleando fórmulas).
Hoy aplicaremos algunas funciones de texto con lenguaje M dentro del editor de Consultas de Power Query:
Text.AfterDelimiter(text as nullable text, delimiter as text, optional index as any) as any
Devuelve la parte de la cadena de texto trabajada después del delimitador especificado. El argumento opcional index indica qué posición del delimitador se debe tener en cuenta.
Además este argumento opcional admite una forma especial de lista, donde podemos definir no solo la posición sino si la indexación debe realizarse desde el principio o el final de la entrada:
{1, RelativePosition.FromEnd}
{2, RelativePosition.FromStart}
Otra función casi idéntica es:
Text.BeforeDelimiter(text as nullable text, delimiter as text, optional index as any) as any
Con significado análogo. Devuelve la parte de la cadena de texto antes del delimitador especificado. El argumento opcional index indica qué posición del delimitador se debe tener en cuenta.
Además este argumento opcional admite una forma especial de lista, donde podemos definir no solo la posición sino si la indexación debe realizarse desde el principio o el final de la entrada:
{1, RelativePosition.FromEnd}
{2, RelativePosition.FromStart}
Una última función M que completa la terna es:
Text.BetweenDelimiters(text as nullable text, startDelimiter as text, endDelimiter as text, optional startIndex as any, optional endIndex as any) as any
Devuelve la parte de la cadena de texto entre los delimitadores especificados: startDelimiter y endDelimiter.
El argumento startIndex indica desde qué posición de startDelimiter se debe tener en cuenta.
Al igual que en las otras dos funciones provias podemos trabajar en los dos argumentos: startIndex y endIndex en forma de lista empleando las funciones RelativePosition.FromStart y RelativePosition.FromEnd
Estas funciones, de alguna manera, potencian el comportamiento de las funciones de hoja de cálculo IZQUIERDA, DERECHA, EXTRAE, LARGO... - homólogas a Text.Start o Text.End
Vamos con nuestro ejemplo... recuerda que vamos a extraer y/o eliminar subcadenas dentro de un texto que cumplan ciertas condiciones, que estén delimitados por un caracter de inicio y otro de fin.

Como siempre fundamental analizar cuáles son los delimitadores!!!.
En la imagen anterior puedes comprobar que he variado los de los ejemplos previos con fórmulas y VBA, y he optado por unas clásicas llaves {}.
A partir de la tabla que contiene las tres cadenas de texto a tratar, y que hemos cargado en nuestro editor de Power Query... generaremos dos funciones personalizadas, que facilitarán nuestra tarea.
La primera función nos permite obtener una lista de coincidencias:
La clave quizá esté en la transformación de la lista 'partida' conseguida con el PrimerSplit... donde trabajamos solo con aquellos elementos de la lista que contengan el delimitador final...
La segunda función será capaz de eliminar las subcadenas coincidentes, como el método .Replace.
OJO con las similitudes!!... y fíjate bien que en la transformación empleamos la función M: Text.AfterDelimeter (a diferencia de la anterior, que empleamos: Text.BeforeDelimeter)...
Con las dos funciones creadas podemos aplicarlas, agregando columnas personalizadas o invocando a funciones personalizadas:
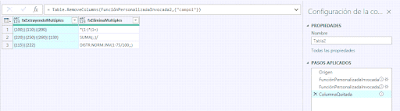
Donde vemos el resultado que queríamos:
Funciones M de texto muy simples pero muy potentes a tener siempre presente ;-)
Hoy aplicaremos algunas funciones de texto con lenguaje M dentro del editor de Consultas de Power Query:
Text.AfterDelimiter(text as nullable text, delimiter as text, optional index as any) as any
Devuelve la parte de la cadena de texto trabajada después del delimitador especificado. El argumento opcional index indica qué posición del delimitador se debe tener en cuenta.
Además este argumento opcional admite una forma especial de lista, donde podemos definir no solo la posición sino si la indexación debe realizarse desde el principio o el final de la entrada:
{1, RelativePosition.FromEnd}
{2, RelativePosition.FromStart}
Otra función casi idéntica es:
Text.BeforeDelimiter(text as nullable text, delimiter as text, optional index as any) as any
Con significado análogo. Devuelve la parte de la cadena de texto antes del delimitador especificado. El argumento opcional index indica qué posición del delimitador se debe tener en cuenta.
Además este argumento opcional admite una forma especial de lista, donde podemos definir no solo la posición sino si la indexación debe realizarse desde el principio o el final de la entrada:
{1, RelativePosition.FromEnd}
{2, RelativePosition.FromStart}
Una última función M que completa la terna es:
Text.BetweenDelimiters(text as nullable text, startDelimiter as text, endDelimiter as text, optional startIndex as any, optional endIndex as any) as any
Devuelve la parte de la cadena de texto entre los delimitadores especificados: startDelimiter y endDelimiter.
El argumento startIndex indica desde qué posición de startDelimiter se debe tener en cuenta.
Al igual que en las otras dos funciones provias podemos trabajar en los dos argumentos: startIndex y endIndex en forma de lista empleando las funciones RelativePosition.FromStart y RelativePosition.FromEnd
Estas funciones, de alguna manera, potencian el comportamiento de las funciones de hoja de cálculo IZQUIERDA, DERECHA, EXTRAE, LARGO... - homólogas a Text.Start o Text.End
Vamos con nuestro ejemplo... recuerda que vamos a extraer y/o eliminar subcadenas dentro de un texto que cumplan ciertas condiciones, que estén delimitados por un caracter de inicio y otro de fin.

Como siempre fundamental analizar cuáles son los delimitadores!!!.
En la imagen anterior puedes comprobar que he variado los de los ejemplos previos con fórmulas y VBA, y he optado por unas clásicas llaves {}.
A partir de la tabla que contiene las tres cadenas de texto a tratar, y que hemos cargado en nuestro editor de Power Query... generaremos dos funciones personalizadas, que facilitarán nuestra tarea.
La primera función nos permite obtener una lista de coincidencias:
(TextoOrigen as text, DelimitadorIni as text, DelimitadorFin as text)=>
let
//convertimos a texto (por si acaso) el texto origen aportado
PasoUNO = Text.From(TextoOrigen),
//partimos por el primer delimitador
PrimerSplit = Text.Split(PasoUNO, DelimitadorIni),
//Eliminamos elementos vacíos que se hayan podido generar tras la separación/split
FiltroContieneFin = List.Select(PrimerSplit, each Text.Contains(_,DelimitadorFin)),
//Text.AfterDelimiter Devuelve la parte del texto después del elemento delimitador especificado
//aplicamos la función elemento a elemento si contiene el DelimitadorFin
RecuperamosTextoAntesDelimitadorFin = List.Transform(FiltroContieneFin,
each
if Text.Contains(_, DelimitadorFin) then
Text.BeforeDelimiter(_, DelimitadorFin, 0)
else _),
//nos quedamos solo con los elementos de la lista con datos
ListaConValor = List.Select(RecuperamosTextoAntesDelimitadorFin, each _<>"" or _<>null),
//y concluimos concatenando los elementos de la lista final
ConcatenamosTexto = Text.Combine(List.Transform(ListaConValor, each DelimitadorIni & _ & DelimitadorFin), "|")
in
ConcatenamosTexto
Esta función replica el método .Execute de RegExp, y por tanto obtendremos un listado de las coincidencias de las subcadenas encontradas entre los delimitadores dados {}.La clave quizá esté en la transformación de la lista 'partida' conseguida con el PrimerSplit... donde trabajamos solo con aquellos elementos de la lista que contengan el delimitador final...
La segunda función será capaz de eliminar las subcadenas coincidentes, como el método .Replace.
(TextoOrigen as text, DelimitadorIni as text, DelimitadorFin as text)=>
let
//convertimos a texto (por si acaso) el texto origen aportado
PasoUNO = Text.From(TextoOrigen),
//partimos por el primer delimitador
PrimerSplit = Text.Split(PasoUNO, DelimitadorIni),
//Eliminamos elementos vacíos que se hayan podido generar tras la separación/split
LimpiamosVacios = List.Select(PrimerSplit, each _<>"" or _<>null),
//Text.AfterDelimiter Devuelve la parte del texto después del elemento delimitador especificado
//aplicamos la función elemento a elemento si contiene el DelimitadorFin
RecuperamosTextoAntesDelimitadorFin = List.Transform(LimpiamosVacios,
each
if Text.Contains(_, DelimitadorFin) then
Text.AfterDelimiter(_, DelimitadorFin, 0)
else _),
//nos quedamos solo con los elementos de la lista con datos
ListaConValor = List.Select(RecuperamosTextoAntesDelimitadorFin, each _<>"" or _<>null),
//y concluimos concatenando los elementos de la lista final
ConcatenamosTexto = Text.Combine(ListaConValor, "")
in
ConcatenamosTextoOJO con las similitudes!!... y fíjate bien que en la transformación empleamos la función M: Text.AfterDelimeter (a diferencia de la anterior, que empleamos: Text.BeforeDelimeter)...
Con las dos funciones creadas podemos aplicarlas, agregando columnas personalizadas o invocando a funciones personalizadas:
let
Origen = Excel.CurrentWorkbook(){[Name="Tabla2"]}[Content],
//extraemos coincidencias con nuestra función
FunciónPersonalizadaInvocada = Table.AddColumn(Origen, "fxExtrayendoMultiples", each fxExtraeMultiples([campo1], "{", "}")),
//eliminamos coincidencias encontradas con nuestra función
FunciónPersonalizadaInvocada2 = Table.AddColumn(FunciónPersonalizadaInvocada, "fxEliminaMultiples", each fxEliminaMultiples([campo1], "{", "}")),
//y quitamos la columna traida de la hoja de cálculo
ColumnaQuitada = Table.RemoveColumns(FunciónPersonalizadaInvocada2,{"campo1"})
in
ColumnaQuitadaDonde vemos el resultado que queríamos:

Funciones M de texto muy simples pero muy potentes a tener siempre presente ;-)


No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.