Como continuación del post anterior, donde exponíamos como obtener para cada registro la diferencia respecto a su dato previo, y recordaremos como llegar al mismo resultado empleando tablas dinámicas.
Curiosamente, hace muchos años (en el 2014) publiqué un artículo sobre este tema precisamente...
Este método nos permitirá comparar técnicas.
Partiremos de la misma tabla trabajada en el artículo anterior comentado:
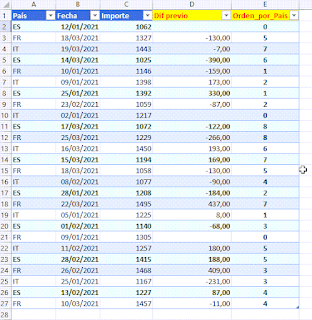
Sobre la tabla creamos un informe de tabla dinámica donde llevaremos el campo 'Importe' al área de valores (DOS veces!); el campo 'Fecha' agrupado por Fecha al área de filas, pero subordinado al campo 'país' también al área de filas.

Sobre el segundo de los campos de 'Suma de Importes' haremos clic derecho, y sobre la opción de 'Mostrar valores como...' buscaremos el cálculo de Diferencia de..., lo que abrirá una ventana diálogo donde configurar este cálculo (revisa el post del 2014 comentado).
Elegiremos como campo base las 'Fechas', y como 'elemento base' el '(Anterior)'

Tras aceptar el resultado es el esperado!!

Comprobamos de qué forma tan simple llegamos a un resultado correcto... punto para las tablas dinámicas ;-)
Curiosamente, hace muchos años (en el 2014) publiqué un artículo sobre este tema precisamente...
Este método nos permitirá comparar técnicas.
Partiremos de la misma tabla trabajada en el artículo anterior comentado:

Sobre la tabla creamos un informe de tabla dinámica donde llevaremos el campo 'Importe' al área de valores (DOS veces!); el campo 'Fecha' agrupado por Fecha al área de filas, pero subordinado al campo 'país' también al área de filas.

Sobre el segundo de los campos de 'Suma de Importes' haremos clic derecho, y sobre la opción de 'Mostrar valores como...' buscaremos el cálculo de Diferencia de..., lo que abrirá una ventana diálogo donde configurar este cálculo (revisa el post del 2014 comentado).
Elegiremos como campo base las 'Fechas', y como 'elemento base' el '(Anterior)'

Tras aceptar el resultado es el esperado!!

Comprobamos de qué forma tan simple llegamos a un resultado correcto... punto para las tablas dinámicas ;-)






















