Tiempo atrás expuse como obtener a partir de nuestro modelo de datos en Power Pivot, y con expresiones MDX y el uso de funciones CUBO (ver) una comparativa del año presente respecto al anterior.
Hoy veremos como las funciones de inteligencia de tiempo en DAX nos pueden ayudar a conseguir ese mismo resultado...

Rapidamente recordaremos las funciones CUBO empleadas en el ejemplo:
- en primer lugar definimos dos cubos de elementos (para años y para comerciales):
En la celda K3: =CONJUNTOCUBO("ThisWorkbookDataModel";
"[Calendar].[Date Hierarchy].&[2013]:[Calendar].[Date Hierarchy].&[2017]";
"Fechas-13-17")
En la celda L2: =CONJUNTOCUBO("ThisWorkbookDataModel";
"{[Tabla1].[Comercial].&[ANA],[Tabla1].[Comercial].&[EVA]}";
"ana+eva")
Por otra parte desplegamos los elementos contenidos en Años en la celda K4:
=MIEMBRORANGOCUBO("ThisWorkbookDataModel";
$K$3;
SECUENCIA(RECUENTOCONJUNTOCUBO($K$3)))
Y finalmente los cálculos agregados para el año corriente en L4:L8:
=VALORCUBO("ThisWorkbookDataModel";"[Measures].[Sum_Ventas]";K4;$L$2)
Para el años previo en M4:M8
=VALORCUBO("ThisWorkbookDataModel";"[Measures].[Sum_Ventas]";"[Calendar].[Date Hierarchy].&["&$K4&"].Lag(1)";$L$2)
donde la expresión .Lag(1) nos trasladaba al periodo anterior de referencia.
Por último, el cálculo acumulado de Todos los comerciales en los años de estudio. En N4:N8
=VALORCUBO("ThisWorkbookDataModel";
"[Measures].[Sum_Ventas]";
K4;
"[Tabla1].[Comercial].&["&MIEMBRORANGOCUBO("ThisWorkbookDataModel";$L$2;1)&"].Parent")
Donde la expresión .Parent recupera el nivel superior del conjunto seleccionado...
Funciones ya explicadas en el post 'linkado'...
Vayamos ahora a Power Pivot a escribir algo de DAX.
Por supuesto, teníamos cargada nuestra tabla en el Modelo de datos, y habíamos generado una Tabla de fechas, relacionando ambas tablas...

A continuación iremos al área de cálculo de la Tabla de datos e insertaremos las siguientes tres medidas:

Las tres medidas se basan en la misma idea: Acumular 'Ventas' al cumplirse múltiples condiciones...
Interesante siempre la manera de acotar los acumulados con distintos FILTROS aplicados...
En el caso de las ventas del año anterior, hacemos uso de la función PREVIOUSYEAR que nos devuelve una tabla que contiene una columna de todas las fechas del año anterior, en función de la última fecha de la columna de fechas del contexto actual.
Con nuestras medidas montadas las trasladamos a nuestra Tabla dinámica del Modelo de datos:
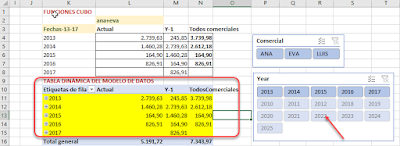
Por supuesto los resultados son iguales en ambos cálculos: DAX vs MDX.
Es interesante ver como al aplicar los distintos filtros en las medidas, afecta a los elementos visibles en la tabla dinámica..
Fíjate por ejemplo en el cuadro de segmentación de los años (traido de la 'tabla de fechas'), donde solo aparecen los años filtrados...
O si quitáramos la medida de 'TodosComerciales', solo veríamos los elementos del filtro: ANA y EVA:

Nuevamente entender correctamente el funcionamiento de los contextos de fila y filtro es fundamental. Saber que, a grandes rasgos, se diferencian en que el contexto de fila representa la "fila actual", y se utiliza para evaluar las fórmulas y expresiones de una columna calculada que usan los iteradores de la tabla.
Mientras que el contexto de filtro se usa para evaluar las medidas, y representa los filtros que se aplican directamente a las columnas y filtros del modelo que propagan las relaciones del modelo (i.e, bien en el modelo, bien en la hoja de cálculo).
Hoy veremos como las funciones de inteligencia de tiempo en DAX nos pueden ayudar a conseguir ese mismo resultado...

Rapidamente recordaremos las funciones CUBO empleadas en el ejemplo:
- en primer lugar definimos dos cubos de elementos (para años y para comerciales):
En la celda K3: =CONJUNTOCUBO("ThisWorkbookDataModel";
"[Calendar].[Date Hierarchy].&[2013]:[Calendar].[Date Hierarchy].&[2017]";
"Fechas-13-17")
En la celda L2: =CONJUNTOCUBO("ThisWorkbookDataModel";
"{[Tabla1].[Comercial].&[ANA],[Tabla1].[Comercial].&[EVA]}";
"ana+eva")
Por otra parte desplegamos los elementos contenidos en Años en la celda K4:
=MIEMBRORANGOCUBO("ThisWorkbookDataModel";
$K$3;
SECUENCIA(RECUENTOCONJUNTOCUBO($K$3)))
Y finalmente los cálculos agregados para el año corriente en L4:L8:
=VALORCUBO("ThisWorkbookDataModel";"[Measures].[Sum_Ventas]";K4;$L$2)
Para el años previo en M4:M8
=VALORCUBO("ThisWorkbookDataModel";"[Measures].[Sum_Ventas]";"[Calendar].[Date Hierarchy].&["&$K4&"].Lag(1)";$L$2)
donde la expresión .Lag(1) nos trasladaba al periodo anterior de referencia.
Por último, el cálculo acumulado de Todos los comerciales en los años de estudio. En N4:N8
=VALORCUBO("ThisWorkbookDataModel";
"[Measures].[Sum_Ventas]";
K4;
"[Tabla1].[Comercial].&["&MIEMBRORANGOCUBO("ThisWorkbookDataModel";$L$2;1)&"].Parent")
Donde la expresión .Parent recupera el nivel superior del conjunto seleccionado...
Funciones ya explicadas en el post 'linkado'...
Vayamos ahora a Power Pivot a escribir algo de DAX.
Por supuesto, teníamos cargada nuestra tabla en el Modelo de datos, y habíamos generado una Tabla de fechas, relacionando ambas tablas...

A continuación iremos al área de cálculo de la Tabla de datos e insertaremos las siguientes tres medidas:
Actual:=CALCULATE(sum([Ventas]);
FILTER(tabla1; (Tabla1[Comercial] IN {"ANA";"EVA"} ));
FILTER('Calendar'; ('Calendar'[Year] >=2013 && 'Calendar'[Year]<=2017)))
Y-1:=CALCULATE(sum(Tabla1[Ventas]);
PREVIOUSYEAR('Calendar'[Date]);
(Tabla1[Comercial] IN {"ANA";"EVA"});
('Calendar'[Year] >=2012 && 'Calendar'[Year]<=2017))
TodosComerciales:=CALCULATE(sum([Ventas]);
FILTER('Calendar'; ('Calendar'[Year] >=2013 && 'Calendar'[Year]<=2017)))
Las tres medidas se basan en la misma idea: Acumular 'Ventas' al cumplirse múltiples condiciones...
Interesante siempre la manera de acotar los acumulados con distintos FILTROS aplicados...
En el caso de las ventas del año anterior, hacemos uso de la función PREVIOUSYEAR que nos devuelve una tabla que contiene una columna de todas las fechas del año anterior, en función de la última fecha de la columna de fechas del contexto actual.
Con nuestras medidas montadas las trasladamos a nuestra Tabla dinámica del Modelo de datos:

Por supuesto los resultados son iguales en ambos cálculos: DAX vs MDX.
Es interesante ver como al aplicar los distintos filtros en las medidas, afecta a los elementos visibles en la tabla dinámica..
Fíjate por ejemplo en el cuadro de segmentación de los años (traido de la 'tabla de fechas'), donde solo aparecen los años filtrados...
O si quitáramos la medida de 'TodosComerciales', solo veríamos los elementos del filtro: ANA y EVA:

Nuevamente entender correctamente el funcionamiento de los contextos de fila y filtro es fundamental. Saber que, a grandes rasgos, se diferencian en que el contexto de fila representa la "fila actual", y se utiliza para evaluar las fórmulas y expresiones de una columna calculada que usan los iteradores de la tabla.
Mientras que el contexto de filtro se usa para evaluar las medidas, y representa los filtros que se aplican directamente a las columnas y filtros del modelo que propagan las relaciones del modelo (i.e, bien en el modelo, bien en la hoja de cálculo).












































