Al trabajar sobre tablas es muy frecuente operar sobre los campos numéricos o incluso de tipo fecha para obtener acumulados, promedios o su valor máximo o mínimo... pero en ocasiones nos interesa recuperar información de campos de tipo texto.
Por ejemplo, ¿cuál es la primera o última descripción que corresponde a tal o cual código?

Hoy mostraré cómo recuperar la primera descripción correspondiente a cada país desde nuestra tabla de información (List.First).
Igualmente recuperaremos la última descripción correspondiente a cada país (List.Last).
Y por último un concatenado de las cuatro primeras descripciones asociadas por país (List.FirstN, además de la ya conocida (Text.Combine)).
Comenzaremos cargando nuestra tabla 'Tabla1' al editor de consultas desde la ficha Datos > grupo Obtener y transformar > Desde Tabla o Rango.
Ya en el editor de Power Query y desde el menú Inicio > grupo Transformar > Agrupar por con la columna 'Código' seleccionada.
En la ventana de configuración aplicaremos las opciones avanzadas, ya que vamos a incluir dos operaciones:
1- una para obtener el valor máximo de 'Ventas' por cada páis
2- una operación cualquiera, que a continuación modificaremos, para recuperar la primera aparición de la descripción

Del código M generado para ese paso:
cambiaremos el que corresponde a la '1st_Descrip' para que quede como sigue:
Se observa que hemos llamado a la función M de
List.First(list as list, optional defaultValue as any) as any
que nos devolverá el primer elemento de la lista indicada. En nuestro ejemplo de la lista correspondiente por cada país que genera nuestra agrupación (Table.Group)

De igual forma podríamos obtener la última descripción que hubiera para cada país.
Mismos pasos que los ya comentados, pero esta vez haciendo uso de la función M:
List.Last(list as list, optional defaultValue as any) as any
pero esta vez devuelve el último elemento de la lista, que para nosotros es la lista de descripciones.
La línea de la agrupación debe quedar como sigue:

Finalmente, veremos un último ejemplo que nos permitirá recuperar en una 'celda', concatenadas, las cuatro primeras 'Descripciones' de cada país.
Emplearemos una función ya conocida que nos permite esa concatenación de elementos de una lista:
Text.Combine(texts as list, optional separator as nullable text) as text
Devuelve el resultado de combinar la lista de valores de texto como un solo valor de texto.
Y por otro lado, para obtener la lista de los cuatro primeros elementos emplearemos:
List.FirstN(list as list, countOrCondition as any) as any
sabiendo que:
-si se especifica un número, se devuelve esa cantidad máxima de elementos.
-y que si se especifica una condición, se devuelven todos los elementos que cumplen inicialmente la condición. (OJO!!: Si un elemento no cumple la condición, no se tienen en cuenta más elementos).
Así pues procederemos de igual forma que en los dos casos previos, esto es, agrupando por la columna 'Código' y modificando la línea del código de ese paso hasta que nos quede como sigue:
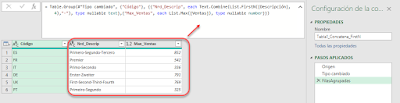
List.FirstN devuelve una lista de hasta cuatro elementos, que luego combinamos en una sola cadena de texto con Text.Combine
Sí, existe una función List.LastN...
Por ejemplo, ¿cuál es la primera o última descripción que corresponde a tal o cual código?

Hoy mostraré cómo recuperar la primera descripción correspondiente a cada país desde nuestra tabla de información (List.First).
Igualmente recuperaremos la última descripción correspondiente a cada país (List.Last).
Y por último un concatenado de las cuatro primeras descripciones asociadas por país (List.FirstN, además de la ya conocida (Text.Combine)).
Comenzaremos cargando nuestra tabla 'Tabla1' al editor de consultas desde la ficha Datos > grupo Obtener y transformar > Desde Tabla o Rango.
Ya en el editor de Power Query y desde el menú Inicio > grupo Transformar > Agrupar por con la columna 'Código' seleccionada.
En la ventana de configuración aplicaremos las opciones avanzadas, ya que vamos a incluir dos operaciones:
1- una para obtener el valor máximo de 'Ventas' por cada páis
2- una operación cualquiera, que a continuación modificaremos, para recuperar la primera aparición de la descripción

Del código M generado para ese paso:
= Table.Group(#"Tipo cambiado", {"Código"}, {{"1st_Descrip", each Table.RowCount(_), Int64.Type}, {"Max_Ventas", each List.Max([Ventas]), type nullable number}})cambiaremos el que corresponde a la '1st_Descrip' para que quede como sigue:
= Table.Group(#"Tipo cambiado", {"Código"}, {{"1st_Descrip", each List.First([Descripción]), type nullable text},{"Max_Ventas", each List.Max([Ventas]), type nullable number}})Se observa que hemos llamado a la función M de
List.First(list as list, optional defaultValue as any) as any
que nos devolverá el primer elemento de la lista indicada. En nuestro ejemplo de la lista correspondiente por cada país que genera nuestra agrupación (Table.Group)

De igual forma podríamos obtener la última descripción que hubiera para cada país.
Mismos pasos que los ya comentados, pero esta vez haciendo uso de la función M:
List.Last(list as list, optional defaultValue as any) as any
pero esta vez devuelve el último elemento de la lista, que para nosotros es la lista de descripciones.
La línea de la agrupación debe quedar como sigue:
= Table.Group(#"Tipo cambiado", {"Código"}, {{"Última_Descrip", each List.Last([Descripción]), type nullable text},{"Max_Ventas", each List.Max([Ventas]), type nullable number}})
Finalmente, veremos un último ejemplo que nos permitirá recuperar en una 'celda', concatenadas, las cuatro primeras 'Descripciones' de cada país.
Emplearemos una función ya conocida que nos permite esa concatenación de elementos de una lista:
Text.Combine(texts as list, optional separator as nullable text) as text
Devuelve el resultado de combinar la lista de valores de texto como un solo valor de texto.
Y por otro lado, para obtener la lista de los cuatro primeros elementos emplearemos:
List.FirstN(list as list, countOrCondition as any) as any
sabiendo que:
-si se especifica un número, se devuelve esa cantidad máxima de elementos.
-y que si se especifica una condición, se devuelven todos los elementos que cumplen inicialmente la condición. (OJO!!: Si un elemento no cumple la condición, no se tienen en cuenta más elementos).
Así pues procederemos de igual forma que en los dos casos previos, esto es, agrupando por la columna 'Código' y modificando la línea del código de ese paso hasta que nos quede como sigue:
= Table.Group(#"Tipo cambiado", {"Código"}, {{"Nrd_Descrip", each Text.Combine(List.FirstN([Descripción],4),"-"), type nullable text},{"Max_Ventas", each List.Max([Ventas]), type nullable number}})
List.FirstN devuelve una lista de hasta cuatro elementos, que luego combinamos en una sola cadena de texto con Text.Combine
Sí, existe una función List.LastN...














































