En la entrada previa veíamos una funcionalidad básica, pero muy potente, de Table.Profile... y adelantaba una opción que nos permite dicha función, como es crear nuestros propios cálculos agregados sobre las columnas de la tabla.
La función tiene la siguiente sintaxis:
Table.Profile(table as table, optional additionalAggregates as nullable list) as table
Y para incorporar el segundo argumento opcional: additionalAggregates deberemos crear una lista con la siguiente estructura:
1- Nombre de la nueva columna
2- definición de sobre qué tipo de dato va a trabajar la columna. Normalmente emplearemos la función:
Type.Is(type1 as type, type2 as type) as logical
de tal forma que solo se trabajará sobre elementos del tipo descrito en la columna.
3- la función de agregado que operará sobre todos los valores de la columna. Habitualmente serán funciones de tipo List (como List.Count, List.Average, List.Median, List.Sum, etc...).
En el ejemplo de hoy realizaremos una búsqueda de un texto para determinar en qué columna se encuentra.
Seguro que muchas veces has necesitado localizar algo en una tabla, y sabrás lo 'pesado' que se hace ubicar una búsqueda en alguna columna... Table.Profile te ahorrará mucho trabajo ;-)
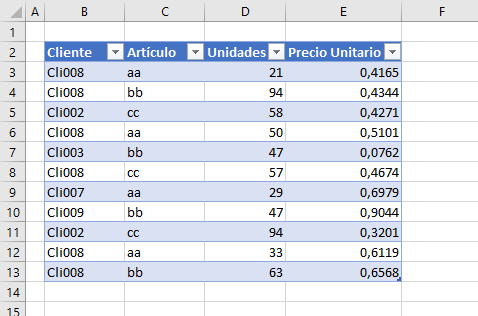
Partiremos del rango siguiente, sobre el que queremos localizar en qué columnas aparece el texto 'Total' (en cualquiera de sus formas)
Cargamos el rango al editor de consultas y escribimos...
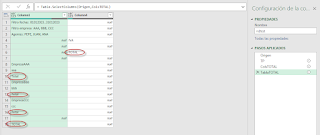
La estructura del argumento de Agregación, para crear nuestro propio cálculo, ha sido:
En la primera parte dábamos el nombre a la futura nueva columna ('contiene' en mi ejemplo)
En la segunda indicamos qué tipo de datos admitimos para el siguiente cálculo. Aquí podríamos indicar cualquier tipo de dato más preciso (number, logical, text, etc...)
Y por fin, en la tercera parte, indicamos el cálculo sobre cada columna. Operamos sobre cada columna, transformada en Lista... Y sobre cada elemento de esa lista, procesamos a su vez, una verificación de Texto.
El objetivo es obtener para cada columna un true o un false según contenga en alguno de sus elementos el texto buscado...
Creo que esta es la forma más sencilla que he trabajado para identificar columnas :OO
La función tiene la siguiente sintaxis:
Table.Profile(table as table, optional additionalAggregates as nullable list) as table
Y para incorporar el segundo argumento opcional: additionalAggregates deberemos crear una lista con la siguiente estructura:
1- Nombre de la nueva columna
2- definición de sobre qué tipo de dato va a trabajar la columna. Normalmente emplearemos la función:
Type.Is(type1 as type, type2 as type) as logical
de tal forma que solo se trabajará sobre elementos del tipo descrito en la columna.
3- la función de agregado que operará sobre todos los valores de la columna. Habitualmente serán funciones de tipo List (como List.Count, List.Average, List.Median, List.Sum, etc...).
En el ejemplo de hoy realizaremos una búsqueda de un texto para determinar en qué columna se encuentra.
Seguro que muchas veces has necesitado localizar algo en una tabla, y sabrás lo 'pesado' que se hace ubicar una búsqueda en alguna columna... Table.Profile te ahorrará mucho trabajo ;-)
Partiremos del rango siguiente, sobre el que queremos localizar en qué columnas aparece el texto 'Total' (en cualquiera de sus formas)

Cargamos el rango al editor de consultas y escribimos...
let
Origen = Excel.CurrentWorkbook(){[Name="ndtest"]}[Content],
//creamos nuestro propio cálculo agregado
//que nos indicará en qué columnas existe el texto 'Total' en cualquiera de sus formas
TP = Table.Profile(Origen,
{ {"contiene",
each Type.Is(_, type any),
each let col=_ ,
rdo=List.AnyTrue( List.Transform(col, each Text.Contains(_,"Total", Comparer.OrdinalIgnoreCase)))
in
try rdo otherwise false } }) [[Column],[contiene]],
//filtramos para obtener únicamente las columnas donde
//nuestro cálculo sea cierto
ColsTOTAL = Table.SelectRows(TP, each ([contiene] = true))[Column],
//Seleccionamos dichas columnas con el texto buscado
TablaTOTAL=Table.SelectColumns(Origen,ColsTOTAL)
in
TablaTOTAL
La estructura del argumento de Agregación, para crear nuestro propio cálculo, ha sido:
...
{ {"contiene",
each Type.Is(_, type any),
each let col=_ ,
rdo=List.AnyTrue( List.Transform(col, each Text.Contains(_,"Total", Comparer.OrdinalIgnoreCase)))
in
try rdo otherwise false } }
...En la primera parte dábamos el nombre a la futura nueva columna ('contiene' en mi ejemplo)
En la segunda indicamos qué tipo de datos admitimos para el siguiente cálculo. Aquí podríamos indicar cualquier tipo de dato más preciso (number, logical, text, etc...)
Y por fin, en la tercera parte, indicamos el cálculo sobre cada columna. Operamos sobre cada columna, transformada en Lista... Y sobre cada elemento de esa lista, procesamos a su vez, una verificación de Texto.
El objetivo es obtener para cada columna un true o un false según contenga en alguno de sus elementos el texto buscado...
Creo que esta es la forma más sencilla que he trabajado para identificar columnas :OO