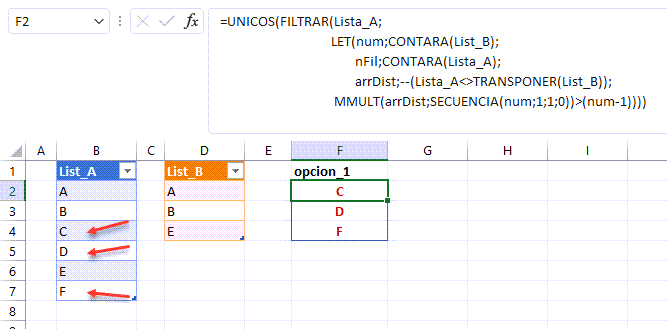
Un concepto obastante interesante a la hora de relacionar distintas fuentes es el Producto Cartesiano.
Una sencilla definición de lo que implica este producto cartesiana sería la que encontramos en Wikipedia:
el producto cartesiano de dos conjuntos es una operación, que resulta en otro conjunto, cuyos elementos son todos los pares ordenados que pueden formarse de forma que el primer elemento del par ordenado pertenezca al primer conjunto y el segundo elemento pertenezca al segundo conjunto.
En definitiva, el producto cartesiano nos devuelve todas las combinaciones posibles entre los elementos de los conjuntos implicados...
El uso, último recurso, de esta operación suele ser relacionar tablas entre sí, las cuales no tiene ningún campo en común... pero que si necesitamos 'unir' para realizaar ciertos cálculos..
Hoy sencillamente realizaremos esta operación para obtener un listado de todas esas coombinaciones posibles entre tres listados.
IMPORTANTE PRECAUCIÓN!!, ya que lo que vamos a obtener es un listado de todas las combinaciones posibles, debderemos tener especial cuidado con el número de elementos de los listados a operar...
Un ejemplo sencillo, si realizamos el producto cartesiano de dos listados, uno de 10.000 elementos, con un segundo listado de 1.000 elementos, el conjunto resultante tendrá: 10.000 x 1.000 = 10.000.000 de registros!!!.
OJO por que esto puede (y lo hará) ralentizar todos nuestros procesos de cálculo.
Pues hechas las advertencias oportunas, veremos cómo conseguir nuestro listado de combinaciones empleando tablas dinámicas!.
Tenemos tres listados o tablas con diferente información: países, colores y números
La meta será conseguir el listado único de todas las combinaciones posibles

Veamos cómo de simple son los pasos para lograr este resultado.
Partimos de una de nuestras tres tablas (cualquiera vale), por ejemplo la de 'países' y la seleccionaremos/activaremos.
El paso siguiente es clave, ya que será en el momento que Insertemos la tabla dinámica donde deberemos marcar una opción importante.
En concreto deberemos selecciona la opción de: Agregar estos datos al modelo de datos
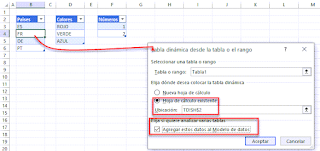
Únicamente realizaremos esta acción sobre una de nuestras fuentes!!!.
Con la tabla dinámica ya creada, iremos al panel de la lista de campos, y seleccionaremos la opción de 'Todas':
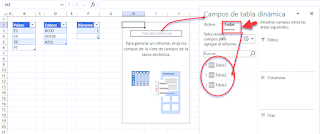
Por 'arte de magia' veremos nuestras tres tablas!!! (ojo, sin relación alguna!!).
En el paso siguiente, muy sencillo, solo llevaremos al área de filas, los distintos campos únicos de nuestros listados...

Ya tenemos el listado buscado... solo nos queda dar un poco de estética (desde la barra de herramientas de Diseño de la tabla dinámica).
1-Cambiaremos el diseño de informe a un modelo en formato tabular.
2-Desactivaremos los Totales generales para filas y columnas.
3-Marcaremos la opción de 'Repetir todas las etiquetas de elementos'.
Listo!!!
Una sencilla definición de lo que implica este producto cartesiana sería la que encontramos en Wikipedia:
el producto cartesiano de dos conjuntos es una operación, que resulta en otro conjunto, cuyos elementos son todos los pares ordenados que pueden formarse de forma que el primer elemento del par ordenado pertenezca al primer conjunto y el segundo elemento pertenezca al segundo conjunto.
En definitiva, el producto cartesiano nos devuelve todas las combinaciones posibles entre los elementos de los conjuntos implicados...
El uso, último recurso, de esta operación suele ser relacionar tablas entre sí, las cuales no tiene ningún campo en común... pero que si necesitamos 'unir' para realizaar ciertos cálculos..
Hoy sencillamente realizaremos esta operación para obtener un listado de todas esas coombinaciones posibles entre tres listados.
IMPORTANTE PRECAUCIÓN!!, ya que lo que vamos a obtener es un listado de todas las combinaciones posibles, debderemos tener especial cuidado con el número de elementos de los listados a operar...
Un ejemplo sencillo, si realizamos el producto cartesiano de dos listados, uno de 10.000 elementos, con un segundo listado de 1.000 elementos, el conjunto resultante tendrá: 10.000 x 1.000 = 10.000.000 de registros!!!.
OJO por que esto puede (y lo hará) ralentizar todos nuestros procesos de cálculo.
Pues hechas las advertencias oportunas, veremos cómo conseguir nuestro listado de combinaciones empleando tablas dinámicas!.
Tenemos tres listados o tablas con diferente información: países, colores y números
La meta será conseguir el listado único de todas las combinaciones posibles

Veamos cómo de simple son los pasos para lograr este resultado.
Partimos de una de nuestras tres tablas (cualquiera vale), por ejemplo la de 'países' y la seleccionaremos/activaremos.
El paso siguiente es clave, ya que será en el momento que Insertemos la tabla dinámica donde deberemos marcar una opción importante.
En concreto deberemos selecciona la opción de: Agregar estos datos al modelo de datos

Únicamente realizaremos esta acción sobre una de nuestras fuentes!!!.
Con la tabla dinámica ya creada, iremos al panel de la lista de campos, y seleccionaremos la opción de 'Todas':

Por 'arte de magia' veremos nuestras tres tablas!!! (ojo, sin relación alguna!!).
En el paso siguiente, muy sencillo, solo llevaremos al área de filas, los distintos campos únicos de nuestros listados...

Ya tenemos el listado buscado... solo nos queda dar un poco de estética (desde la barra de herramientas de Diseño de la tabla dinámica).
1-Cambiaremos el diseño de informe a un modelo en formato tabular.
2-Desactivaremos los Totales generales para filas y columnas.
3-Marcaremos la opción de 'Repetir todas las etiquetas de elementos'.
Listo!!!